I get asked from time to time: Why do I include so [redacted] many links in pages on my blog? This blog’s about page, my StackOverflow profile, even my CV…they’re full of links to other people’s cool stuff. It’s a public service, really. I’m such a giver.
The reason is twofold:
- It helps readers.
- It helps the people I cite.
Helping readers
Adding a boatload of links to a page means you, dear reader, can get to the content you want. It also makes the page easier for one to read.
Connecting
If someone is flipping through my CV and has never heard of the Robert S. Hyer Society or the Harvard–Amgen Scholars Program, there’s a handy, unobtrusive link in the PDF that they can click or tap—just like on a webpage.

Including links is also a great way to help readers call bullshit. If you make a grandiose claim, you’d better back it up. I take this seriously in my CV. If I give a presentation, I link to it. If I win an award, I link to it. Forget fake news. You can verify it yourself, and I make it easy by pointing to people better-known than I am.
Interpretability
When done right, links help you to segment content when you’re reading.
English is notorious for this thing where stringing nouns together gives you a new, modified noun. (German does this, too, but better. They drop the spaces in between. Informally, I’d like to see English compounds like summerprogram.) Donald Knuth sees this as a problem:
Resist the temptation to use long strings of nouns as adjectives: consider the packet switched data communication network protocol problem.
And you wouldn’t be so bold as to disagree with him, would you?
But when there’s that magic blue underline, you know the words belong in a group together. (A+ example: up above, the words “about page”.) This makes it easier to mentally parse, and not sending you down a garden path makes it easier to read.
This places a burden on the linker: make sure what you’re underlining fits under one grammatical tag. Earlier in this section, I underlined the entire verb phrase “sees this as a problem”. You’d tweak your eyebrow a bit if I had skipped underlining “sees”.
Helping people I cite
It’s simple: the rich get richer. If a person or website has been helpful or important to me, a small act of repayment is attribution. (In fact, academics live and die by citation.) In linking to someone else’s resources, I make them more visible. And that’s good for them.
I don’t mean to suggest some massive viewership for this blog. No, citation helps people by the magic of Google. (Or Bing. I use Bing because Bing pays money. Is it worth the hours lost from inferior academic search results? Compare Bing vs Google.)
PageRank was what made Google a hit. Named after Larry Page (and not a webpage), it ranks results based on the reputation other pages give them.
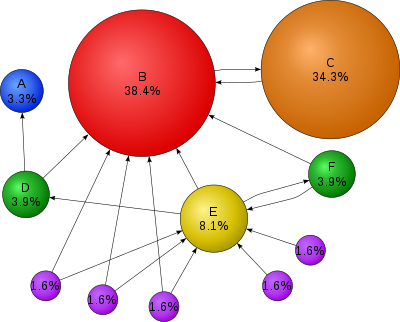
There’s some basic linear algebra that goes into how the weights come about, but the gist is a story of cumulative advantage. Pages with more links to them get more reputation, and that means they (a) show up higher in lists, and (b) have more impact on pages they link to. See how in the figure, C is different from the handful of other pages that link to B because super-popular B links back to C. B is claiming that there’s something worthwhile in C, and because of B’s high reputation, the claim carries a lot of weight.
I see myself as one of the purple dots, though. If I link to a E and make it more visible, then I make their reputation (and weight) greater. That’s how pointing to things and people I like helps them out. It makes them more powerful influencers. With more visibility, they can do more.
It’s a golden-rule sort of thing (or at least, a categorical imperative): link unto others as you would have them link unto you. If you’re providing helpful content, people help both you and strangers by linking.
The bottom line
Readability, access, verification, influence. Be kind to others. Link.






 Large-scale trunk lines for communicating in the USA
Large-scale trunk lines for communicating in the USA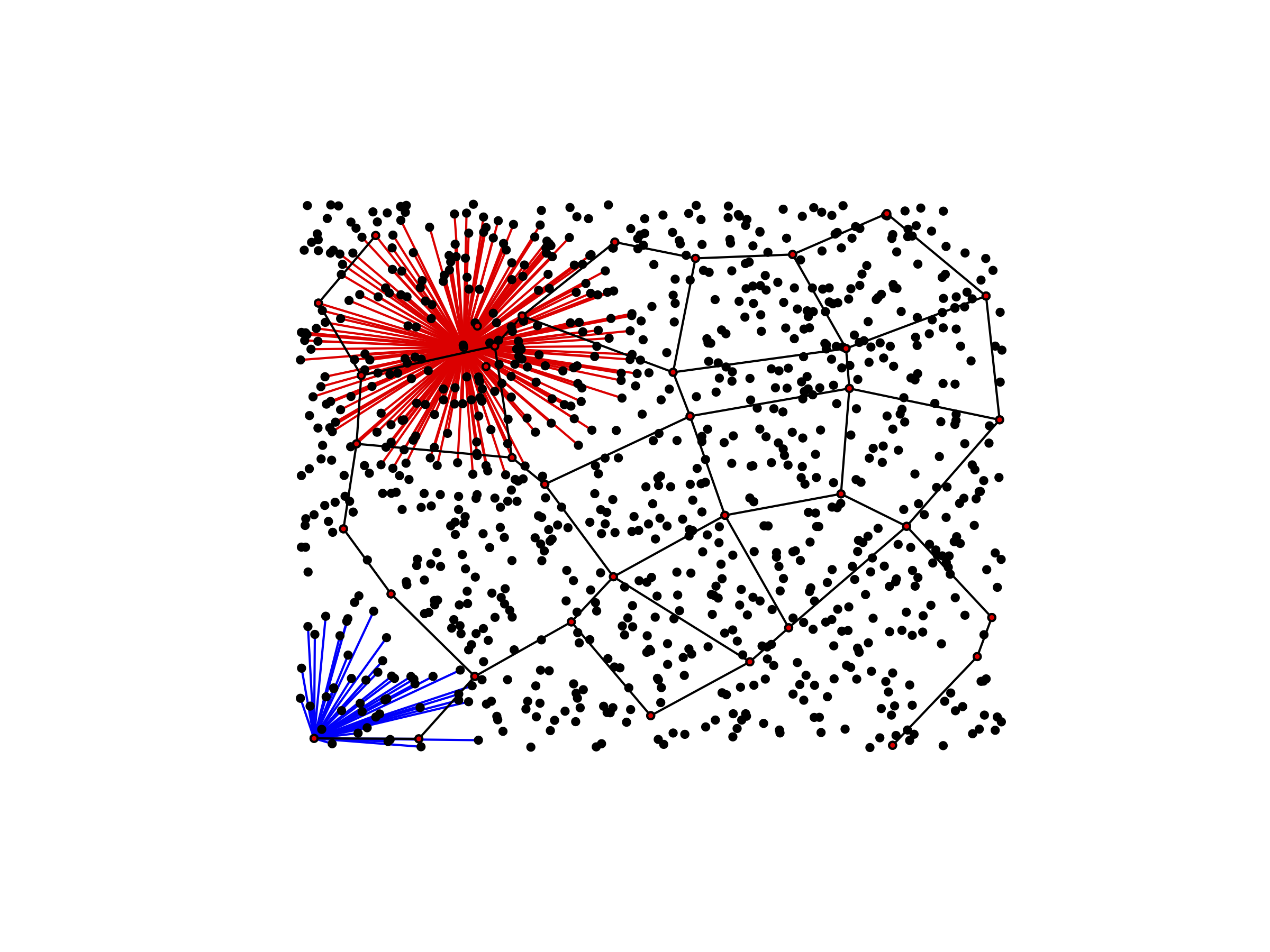 Nodes marked in red form the backbone with the greatest coverage, and black edges connect the backbone. The red edges connect a single node to all of its neighbors.
Nodes marked in red form the backbone with the greatest coverage, and black edges connect the backbone. The red edges connect a single node to all of its neighbors. The terminal clique is discernible at the far left of the graph, where the slope is consistent.
The terminal clique is discernible at the far left of the graph, where the slope is consistent.