
Phylogenetics of Indo-European Language Families via an Algebro-Geometric Analysis of their Syntactic Structures
(Shu et al., 2017) on arXiv
I’m starting a new thing where I write about a paper every day, inspired by The Morning Paper. Let me know what you think.
Shu et al. look at the similarities and descencdance between languages using the same techniques for comparing phylogenies of organisms. This isn’t the first time that this similarity has been looked at, but their model lets language families be compared to each other.
If languages were completely randomly designed, we wouldn’t expect nearly the level of cognate words and similarity in sentence structure that we see. These occur because languages developed from shared ancestors, much like the evolution of organisms. On top of that, languages are able to exchange parts of their design—something organisms can’t.
For instance, the Spanish vivir and French vivre, both “to live”, both descend from the Latin verb whose infinitive is vivere—the evolution process. And the Japanese loan word コンピューター (Konpyūtā) comes from the English word computer, even though the languages are extremely unrelated.
In modeling this, they try to avoid Swadesh lists, because of some problems they believe to exist in them. Swadesh lists are essentially a big table, with ideas as rows and languages as columns. Each cell contains the word in that language which expresses the idea. (A recent, exciting one I found was NorthEuraLex, which also gives the IPA encoding.) Unfortunately, these can be misled by “synonyms, loan words, and false positives”.
They make the claim that syntactic data is easier to binary-encode than morphological data. I wonder if they know the UniMorph project. I expect that using UniMorph would lead to self-fulfilling prophecies because the annotations come from different human annotators. Still, they say that they avoid that by tailoring the model to smaller sets of languages annotated similarly.
For Germanic languages, they came up with six possible splits into trees. Sounds like their method broke for Romance languages, though.
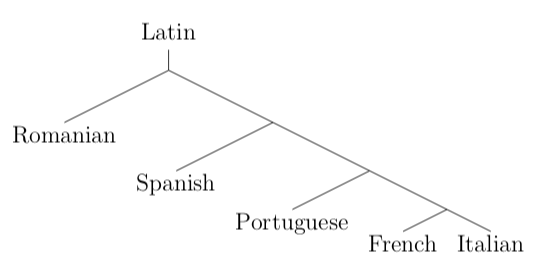
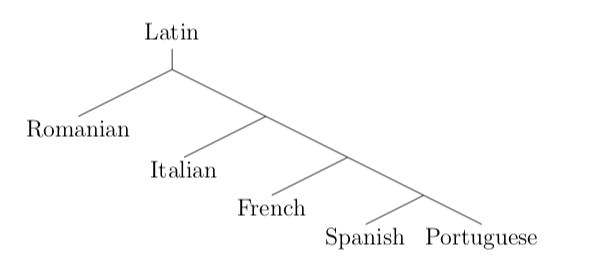
The right answer should look like a tree splitting east-to-west. Later they give some thoughts about why this happened.
Their model is a Markov process on a binary tree, with a symmetric (doubly-stochastic) transition matrix. This entails a stationary distribution with final probabilities 1/2 for each state.
“In phylogenetic linguistics the presence of a non-binary tree denotes an ambiguity, which should eventually be resolved into one of its possible binary splittings.” They’re able to split ternary splits into any of the three possible binary splits, and the results are identical except the position of the root. (Their model doesn’t specify a root.) But we as linguists love our root nodes, so this is a bit upsetting. This is slightly solved, though, when we have access to older versions of the language.
The authors note that the independence assumption their model makes may have caused problems with the Romance languages, which are not independent. Because their models required so much finessing and back-checking to conform to known data about languages, I can’t take their result about the development of early Indo-European languages as gospel. Still, their phylogenic model is interesting, and I’m always happy to see more attention given to historical linguistics.