
Character Sequence Models for Colorful Words
(Kawakami et al., 2016) at EMNLP
Today we get to rip of NMT literature for multi-modal work. This time for predicting colors given their names. Woo hoo. Also, they’ve got a demo going. Type words, get colors.
This paper relies on databases of color names. They’re sparse, so the authors use character-level representations instead. (This is a surprisingly underemphasized point.)
They create a model that turns color names into color coordinates. They evaluate the model with a “color Turing test”: the generated names are typically preferred over the human-devised names for the colors. They also produce the opposite: a generative model of color names given their coordinates in color space.
Color spaces are an interesting matter. While RGB is widespread (representing a color as a triple in {0,…,255}^3), the authors prefer Lab, which lets Euclidian distances better match human-perceived differences. This is better for gradient optimization.
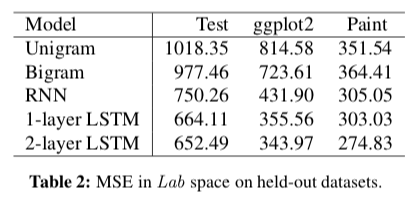
The authors first try to predict the Lab coordinates using the name. They train on a large corpus of names from a popular online website. They use the color names of the ggplot2 package and the paint colors of Sherwin Williams as held-out evaluation.
To do this, they embed each character of the input sequence as a 300-dimensional vector. They pipe the sequence of character embeddings into an LSTM encoder with 300 hidden units. The last hidden state is a 300-dimensional representation of the sequence. (This sounds like ripping off the encoder–decoder architectures from NMT, before they got smart about attention.) The encoding is then fed through a linear layer and a nonlinearity (so basically a fully connected layer with a nonlinearity), giving the three coordinates as the output.
They optimize using the reference labels for each color name, optimizing the mean squared error between the true and computed coordinates. Their LSTM and non-LSTM RNN approaches outperform simple linear regression using the bags of character unigrams and bigrams. Honestly, the comparison seems a bit mean given the relative expressive powers of the model. It also makes the bigram model’s performance much more impressive—or makes their models less impressive.
Now for the color Turing test. The authors showed both their generated color and the true color to over 100 judges for each of 20 examples. They found that their model’s coordinates were preferred by at least a 13.5-point margin.
And if I thought this sounded like MT before, they’re definitely ripping it off now. They go back from their tiny coordinates for a color to a 300-dimensional representation, then perform autoregressive decoding on it with an LSTM. This is, like, page 1 of the NMT playbook. Each next character comes out of an MLP layer (read: affine transformation) followed by a softmax to produce a probability distribution over letters in the current position.
They also try a variational autoencoder (VAE) approach that I’m just not going into. It’s a way of squeezing in a latent variable to give the model greater capacity. They evaluate this approach and the NMT decoder (the “LSTM language model”) in terms of perplexity. The VAE did better. (Someday, someone needs to write a Kevin Knight-style tutorial on VAE).