
Optimizing Segmentation Granularity for Neural Machine Translation
(Salesky et al., 2018) on arXiv
Byte pair encoding (BPE) is now a standard way to preprocess data in neural machine translation. It combats data sparsity by creating a vocabulary of subwords to use instead of words. The subword units may be more common than the words, especially in morphologically rich languages. The question remains how many subwords to use. People tend not to sweep this hyperparameter. This paper does it automatically (for the target-side vocabulary), without adding training time. It doesn’t make a huge improvement in BLEU score, but it’s a fascinating method.
There’s a tradeoff in selecting the optimal hyperparameter. Too small a vocabulary and your model must correctly predict many subwords in a row to produce the intended word. Too large, and you make individual words infrequent.
The proposed method of incremental BPE has two parts: a schedule of merge operations and a way to initialize new embeddings for members of the growing vocabulary.
Their schedule for expanding the vocabulary depends on validation loss during training. If validation loss has plateaued, the vocabulary is expanded to the next size in the schedule. (The authors use 10k, 20k, …, 60k.) This supposedly achieves the same performance as grid search.
To initialize the new embeddings, the authors try three approaches:
- Random: Initialize the new, merged vocabulary item with a random embedding.
- Average: Take the arithmetic mean of the two merging items’ embeddings as the merged item’s embedding.
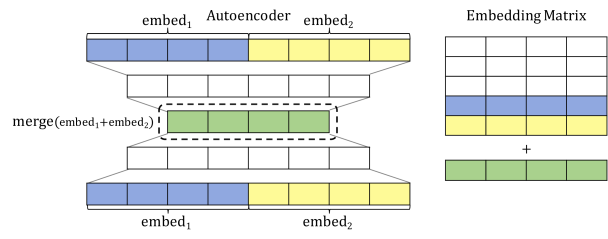
- Autoencoder: Train a small network to predict the two items’ embeddings, given those embeddings. The middle hidden layer should be the size of only one embedding. After training the network, this value is used as the new, merged item’s embedding. This one works best.
The authors use standard datasets (WMT and IWSLT) for training from English into a morphologically rich language: Czech or German. They found that optimal performance on smaller datasets may come from fewer subword units, and that the same number of units wouldn’t be optimal across datasets.
Their incremental approach would typically underestimate the optimal vocabulary size from the grid search, but the performance beats the sweep result with the same vocabulary size.
Altogether, an interesting and useful paper with the message that fixing a hyperparameter is a bad idea. The fact that it can be effectively tuned inline during training is especially impressive.