
Automatic Discrimination between Cognates and Borrowings
(Ciobanu and Dinu, 2015) at ACL
It is said that “no man is an island.” Most definitely, no language is an island. They borrow from one another to extreme degrees. Today’s paper comes from two authors at the University of Bucharest, in the middle of the notorious Balkan Sprachbund. This is a natural area to study the difference between cognates—which came from a shared ancestor—and borrowings. They use orthography to discern.
Borrowings are a problem for step 1 of the comparative method, because it can give false positives when assembling your list of cognates. This makes languages seem phylogenetically closer than they really are.
The best tool for discerning between cognates and borrowings is the correspondence sets Campbell described. If the sound alignment is regular across many words, it’s a cognate. The authors posit that this is sufficiently reflected in orthography.
To test this hypothesis, the authors study Romanian paired with the three big, easy Romance languages (Spanish, Portuguese, Italian—avoiding the orthographic nightmare of French) and Turkish, from which Romanian has borrowed. Turkish and Romanian also share cognates of French origin, though this use of “cognate” is suspect.
As features, they extract monotonic n-gram alignments (no crossing lines) between pairs of words, then feed them either into naive Bayes or a support vector machine (SVM). These alignments can be produced whether the word is a cognate or a borrowing, and the hope is that the distribution of n-gram alignments differs.
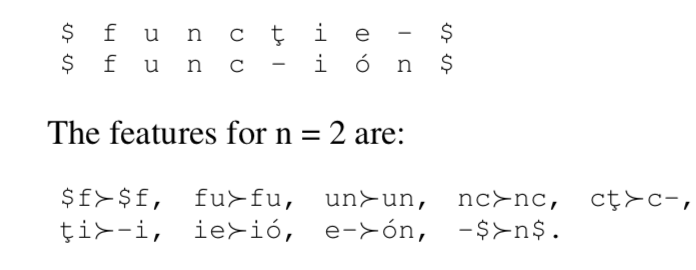
On top of this, they perform an ablation study—adding and removing features to see which ones are most important. The features they mix in are part-of-speech tags, syllabication, and “consonant skeletons” (because these change at a slower pace than vowels), stems, and diacritics. None of them really help.
As far as results, they’re able to get F1 scores of >85.0 for 3 of the 4 languages. It’s not strictly clear why Italian fares so poorly or Turkish fares so well. There’s little error analysis in this paper, but it’s conceivable that the Turkish “cognates” from French look different from Turkish borrowings. They just naturally have a different bigram distribution. Italian, though, should be the most similar language of the three to Romanian. And again, Portuguese and Romanian are inexplicably linked—the performance here is highest of any.
I’d like to see this fed into another system like Hall and Klein’s, because it’s helpful to know how much this improves the entire comparative method pipeline. It’s a short paper, though. Fingers crossed for a followup. Also, the method is supervised. Maybe apply some clustering to these, so we can apply the method to untested language pairs? And get adversarial—put some absolutely unrelated word pairs. The authors do talk about using a test of relatedness as a prior step, but it would be nice to see that integrated.
My favorite thing about this paper, though, is that it’s such an explicit model that you could go and implement it yourself in an afternoon or so.
TL;DR: bigrams are useful features for classifying related word pairs as cognates or borrowings.