
Non-Autoregressive Neural Machine Translation
(Gu et al., 2017) on arXiv; submitted to ICLR 2018
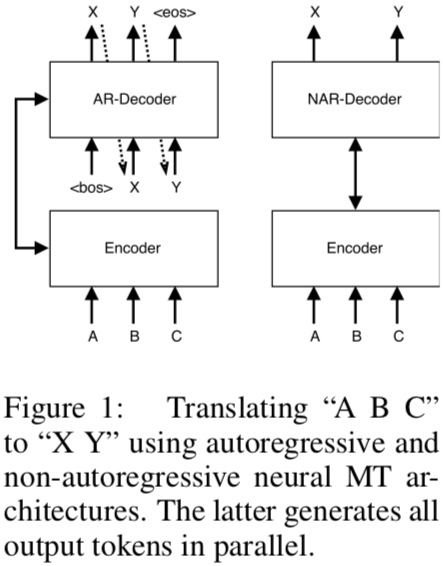
Neural machine translation is slow because of how we decode. This paper calls the popular method “auto-regressive”: each output token depends on all previous tokens. This is inherently sequential and cannot be parallelized, so this paper introduces the workaround. There’s nothing new under the sun—they reintroduce the fertility parameters from the old IBM models. They also rely on an auto-regressive teacher, so the model is trying to see farther by standing on the shoulders of giants.
Picking the autoregressive factorizing of the NMT model makes training easy: maximize the log likelihood, is a simple sum. Each step is completely supervised. The RNN decoder in the model can even be replaced with CNNs or Transformer, a hip new method I should write about soon. Sounds like these are plain old MLP encoders and decoders linked by attention.
Decoding is a different matter. Beam search is fast and near-optimal, but it’s sequential. Plus, larger beams only help for so long. So how do we speed it up? Do we make each output token depend only on the input sequence, not previous terms? No! Because the tokens do depend on each other. You can’t wave your hands and wish away that conditional dependence.
Enter the “Non-Autoregressive Transformer”, or NAT for short. It’s based on the MLP encoder–decoder structure of the Transformer architecture, but with a different decoder. The decoder now has a number of outputs determined by the fertility parameters of the input words. Fertility came out of IBM Model 3. It’s a latent variable for the model to learn jointly with the others.
An interesting dilemma in their model is that because you don’t condition on earlier parts of the sentence, you can accidentally goof up without a trick they introduce.
In many cases, there are multiple correct translations consistent with a single sequence of fertilities—for instance, both “Danke schön.” and “Vielen dank.” are consistent with the English input “Thank you.” and the fertility sequence [2, 0, 1], because “you” is not directly translated in either German sentence.
(Note that the period counts as a token; that’s why it’s [2, 0, 1], not [2, 0].) They teach their model to greedily prefer the outputs that an autoregressive model prefers, building on what already exists. It seems that they’re trying to distill the knowledge of the autoregressive model into a model that can decode quickly, regardless of its training time. The whole process gets them to within 2.0 BLEU points of the teacher—not bad.
From the authorship, it’s easy to see why they’re willing to sacrifice BLEU for faster models. Four of the five authors are at Salesforce, rather than in academia. It takes a long time to train, but they’ll only need to train it once. Plus, when you’re dealing with massive volume, computation time counts. The NAT architecture is for squeezing every last second out. Plus, because it learns from a teacher, it will improve as autoregressive models remove.
The bottom line: This is the first neural MT model that’s entirely parallel. The MLP encoder and the non-autoregressive decoder make it fast. Still, it relies on other models to teach it, plus a bunch of hacky tricks to avoid performance loss from the breakdown in conditional dependence, so it’s unlikely to stand alone.